什么是HDFS
什么是HDFS(Hadoop Distributed File System)?当数据集的大小超过一台独立的物理计算机的存储能力时,就有必要对它进行分区(partition)并存储到若干台单独的计算机上。管理网络中多态计算机存储的文件系统成为分布式文件系统(distributed filesystem)。HDFS是Hadoop自带的分布式文件系统。
数据块
HDFS采用128MB的数据块。其目的是为了最小化寻址开销。如果块足够大,从磁盘传输数据的时间会明显大于定位这个快开始位置所需要的时间。因此,传输一个由多个快组成的大文件的时间取决于磁盘传输速率。
namenode和datanode
- HDFS集群有两类节点以管理节点(namenode)-工作节点(datanode)模式运行。
- namenode管理文件系统的命名空间。它维护文件系统树和整颗树内的所有文件和目录。这些信息以两个文件的形式永久保存在本地磁盘:命名空间镜像文件和编辑日志文件。
- client代表用户通过namenode与datanode进行交互来访问整个文件系统。客户端提供一个类似于POSIX(可一直操作系统界面)的文件系统接口。用户在编程的时候无需知道namenode和datanode也可实现其功能。
- datanode是文件系统的工作节点。他们根据需要存储并检索数据块,并定期向namenode发送他们所存储的块的列表。
- namenode用来控制datanode的块来重建文件。如果没有namenode,文件系统将无法使用,甚至运行namenode服务的机器出现损坏,文件系统上的所有文件将会丢失,因为一个文件被分成了多个数据块存储在多个datanode上,我们并不知道如何根据datanode的数据块来重建文件。因此要对namenode实现容错。
HDFS的高可用性
在hadoop2中,实现HDFS的高可用性,即实现了namenode容错快速重建。
- 联合使用多个文件系统备份namenode元数据。
- 使用备用namenode创建监测点防止数据丢失。
- hadoop2实现(active-standby)namenode。即当活动namenode失效,备用namenode就会接管它的任务开始服务客户端。但需要datanode同时向两个namenode发送数据块处理报告。
Hadoop模式配置
参考Hadoop权威指南附录A
Hadoop的各个组件都可以利用xml文件进行配置,放置在hadoop根目录/etc/hadoop/。
- core-site.xml文件用于配置通用属性
- hdfs-site.xml文件用于配置HDFS属性
- mapred-site.xml文件用于配置MapReduce属性
- yarn-site.xml文件用于配置YARN属性。
Hadoop有三种运行模型:
- 独立模式:无需运行任何守护进程,所有程序都在同一个JVM上执行。在独立模式下测试和调试MapReduce程序很方便,因此该模式在开发阶段比较合适
- 伪分布模式:Hadoop守护进程运行在本地机器上,模拟一个小规模的集群。
- 全分布模式:Hadoop守护进程运行在一个集群上。
不同的模式下关键配置属性
| 组件名称 | 属性名称 | 独立模式 | 伪分布模式 | 全分布模式 |
|---|---|---|---|---|
| Common | fs.defaultFS | file:/// | hdfs://localhost/ | hdfs://namenode/ |
| HDFS | dfs.replication(文件备份数量) | N/A | 1 | 3(默认) |
| MapReduce | mapreduce.framework.name | local(默认) | Yarn | yarn |
| YARN | yarn.resourcemanager.hostname | N/A | Localhost | resourcemanager |
| yarn.nodemanager.aux-services | N/A | mapreduce_shuffle | mapreduce_shffule |
独立模式无需运行任何守护进程,因此在独立模式下不需要更多操作。
伪分布模式
在上述四个*-site.xml文件中添加上述表中的内容
1 | core-site.xml |
配置ssh
伪分布模式下必须启动守护进程,启动守护进程的前提是ssh。在伪分布模式下,主机就是本地计算机localhost。需要保证用户能够用ssh连接到本地主机。具体就是将/usr/root/用户的id_rsa.pub添加到/usr/root/的authorized_keys中实现免密登录。
格式化HDFS文件系统,其实就是格式化namenode节点
1
hdfs namenode -format
启动和终止守护进程
1
2
3
4
5
6
7
8
9启动守护进程
start-dfs.sh
start-yatn.sh
mr-jobhistory-daemon.sh start historyserver
终止守护进程
mr-jobhistory-daemon.sh stop historyserver
stop-yarn.sh
stop-dfs.sh
本地计算机localhost将启动守护进程,一个namenode,一个附属namenode,一个datanode(hdfs), 一个资源管理器,一个节点管理器(yarn)和一个历史服务器(mapreduce)。可以在hadoop安装目录下的logs中检查文件日志来检查守护进程是否成功。
或者通过Web界面:
http://localhost:50070/查看namenode,
http://localhost:8088/查看资源管理器
http://localhost:19888/查看历史服务器但问题是CentOS7最小安装是命令行模式,不会有浏览器让你查看。解答:CentOS 7 最小化安装添加图像化界面
创建用户目录
1
2hadoop fs -mkdir -p /user/$USER
第一次不知道我就使用了/user/root/ 但为了避免歧义,还是选择其他名字吧HDFS命令行接口
HDFS有很多接口,其中命令行是最简单的。
文件系统基本操作: hadoop fs -help 来获取命令帮助HDFS文件目录显示
命令:
1
hadoop fs -ls /user/root

第1列为文件权限模式,与POSIX模式相同(777),目录为d
第2列为该文件的备份数(由于我们选择了伪分布模式,在dfs.replication配置中选择了1)
第3,4列为文件所属用户和组别。
对于文件而言,你不能在HDFS中执行文件,所以所有文件都不可执行。对于目录而言,要访问一个目录的子项,必须需要x权限。*
默认情况下,Hadoop运行时安全措施处于停用模式,意味着客户端身份是没有经过认证的。由于客户端是远程的,一个客户端可以在远程系统上通过创建和任何一个合法用户同名的账号来进行访问。无论怎样,为了防止用户或者自动工具及程序意外修改或删除文件系统的重要部分,启动权限控制很重要(dfs.permissions.enabled默认属性)
super-user的概念,超级用户是namenode进程的标识,对于超级用户,系统不会执行任何权限检查。
HDFS文件系统:
- Hadoop有一个抽象的文件系统,HDFS只是其中的一个实现。Hadoop对文件系统提供了多个接口,它一般使用URI方案来选取合适的文件系统实例进行交互。
- 通过Java API可以调用大部分Hadoop文件系统的交互操作。
参考Hadoop权威指南第三章的代码。
这里重点说明一下使用maven编译hadoop程序的流程。以编译ch3-URLCat.java为例:
按照上述hadoop流程建立hdfs守护程序,采用伪分布模式
建立maven项目工程,并在/src/main/java/下编写URLCat.java程序
使用命令 %mvn clean compile 在根目录下对项目进行编译。此时会在文件根目录生成一个target目录。注意每一次clean compile都会完全清除target目录下的所有内容,然后再对项目进行编译。
编译不成功,显示error找不到包,此时需要在pom.xml文件中添加dependencies.如下:
1
2
3
4
5
6
7
8
9
10<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.9.2</version>
</dependency>保持网络连接,继续用上述编译命令进行编译,会从apache网站下载相关包(国内注意配置阿里云镜像)
编译成功,在target中生成class文件
在hadoop权威指南中直接用hadoop URLCat hdfs://localhost/user/root/quangle.txt来执行了命令,是因为它把整个项目生成了一个jar包放在了classpath里。
目前我们新建的项目还没有生成jar包,就需要把该生成的URLCat.class文件打包成jar包。
%jar -cvf xxx.jar xxx.class运行Hadoop命令
1
hadoop jar xxx.jar xxx hdfs://localhost/user/root/quangle.txt
Hadoop文件系统数据流
附上两张关于hdfs的读写操作:
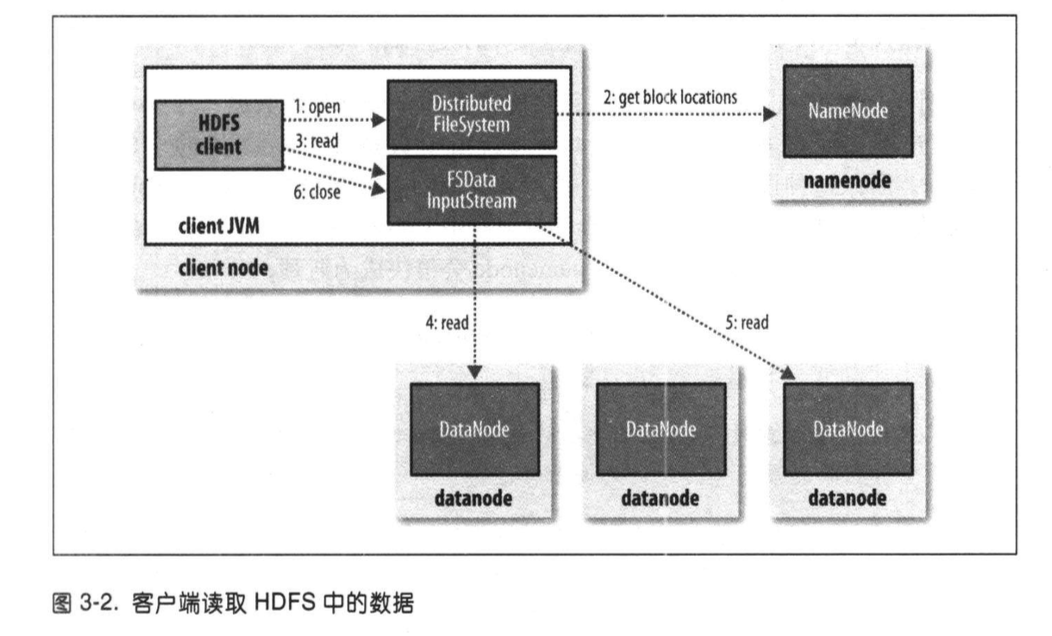
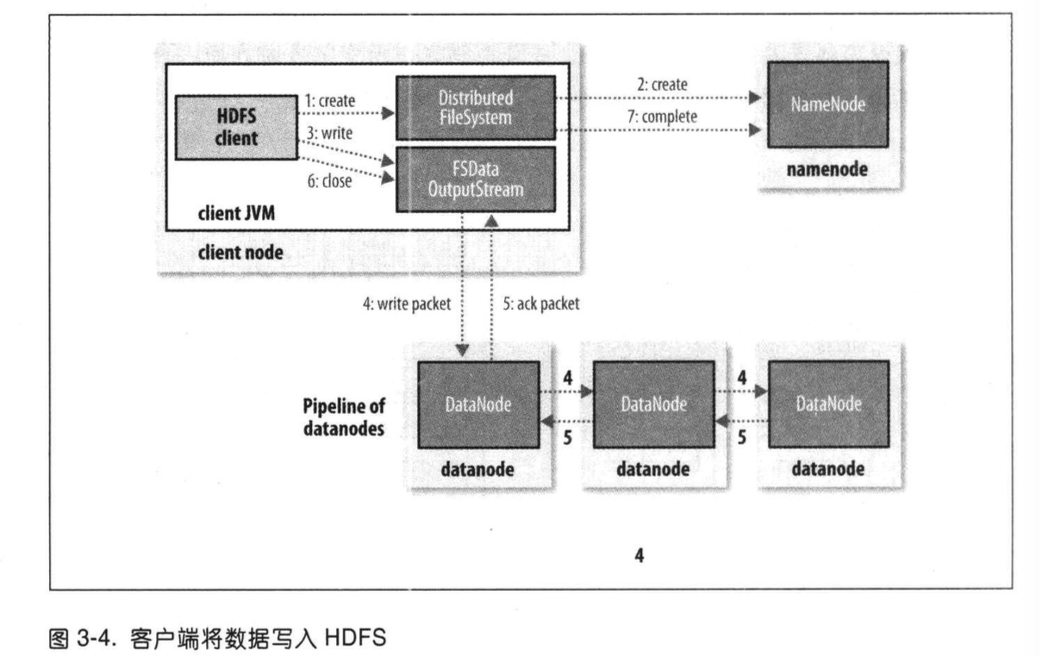
其实通俗的讲,就是namenode保存了文件重建的方法,并在读写过程中将中将如何重建告诉主机中的文件系统,文件系统按照该重建方法从datanode中读取或写入数据。这一过程对客户端来说是透明的。
守护程序就是namenode与datanode不断进行沟通,更新在哪个datanode上存着那一部分数据。