通过编写WordCount来探索RDD编程,还是没能完全改成函数式编程,所以这里的代码主要使用了Java API,即使是函数式编程也是在Java1.8下的。没有在scala下。稍微有些不习惯scala下var和val自动定义变量类型。
SparkConf
每一个Spark任务都需要一个driver执行所有的操作,那么每一个spark程序的开头都是定义这么一个driver。在wordcount应用中,只需要定义driver的名字和master就可以了。
SparkContext
SparkContext是Spark应用程序中用到的第一个类。SparkContext为Spark的主要入口点,简明扼要,如把Spark集群当作服务端那Spark Driver就是客户端,SparkContext则是客户端的核心。
SparkContext用于连接Spark集群、创建RDD、累加器(accumlator)、广播变量(broadcast variables)。
wordcount程序基本只需要创建RDD,那么创建RDD有两种基本方式:
- 从文件中读取 textFile()
- parallelize()
例如:
通过textFile()建立
1 | SparkConf conf = new SparkConf(); |
注意src_file的路径有两种方式:
- 位于hdfs上的路径采用
hdfs://前缀 - 位于主机本地上的路径采用
file://前缀
通过parallelize()建立
1 | SparkConf conf = new SparkConf().setAppName("text"); |
RDD操作
我们想要实现统计一段文本中出现频率最高的单词。也就是说结果是单词按照词频降序排列。那么应该想到有以下步骤:
- 分词,String->String.iterator 从长文本变为单词迭代器。这就设计到了转换,使用flatMap
map与flatMap的区别:
- map()是将函数用于RDD中的每个元素,将返回值构成新的RDD。
- flatmap()是将函数应用于RDD中的每个元素,将返回的迭代器的所有内容构成新的RDD
- 赋值词频1,String-> <String, 1> 用到map
- 合并词频,<String, 1> -> <String, v> 用到reduce
- 按照词频排序,首先要将key变为词频计数。<String, v> -> <v, String>, 用到map
- 按key排序,用到sortByKey(false)。false表示降序
- 输出结果并保存。启用设定格式,去掉括号,用到map
整体代码如下:
1 | /** |
编译提交
maven编译参考Spark环境搭建与RDD编程基础
提交:spark-submit --master "localhost:7077" ./spark-rdd-0.0.1-SNAPSHOT.jar
RDD Tips
在RDD编程的过程中一定要先想好你想要的结果是什么,然后再去选择合适的RDD编程架构。
在上述代码中,结果会出现如下:
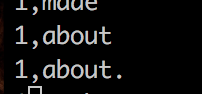
所以在分词的过程中,不仅要添加空格还要添加可能的标点符号。
所以需要使用正则表达式进行字符串分隔。
return Arrays.asList(t.split("[\\p{Punct}\\s]+")).iterator();