- RDD是什么
- RDD常用操作
1. RDD是什么
RDD是Spark对数据的核心抽象(弹性分布式数据集 Resilient Distributed Dataset)。其实就是分布式的元素集合。在spark中,对数据的所有操作都基于RDD创建,RDD Transformation,RDD Action。在这个过程中,spark会自动将RDD中的数据分发到集群上,并将操作并行化执行。
RDD是一个不可变的分布式对象集合。每个RDD都被分为多个分区,这些分区运行在集群中的不同节点上。
每个spark程序或shell会话都会按照如下方式工作:
(1)从外部数据创建出输入RDD
(2)使用诸如filter()这样的转化操作对RDD进行转化,以定义新的RDD
(3)告诉spark对需要被重用的中间结果RDD执行persist()操作,或cache()
(4)使用行动操作来触发一次并行计算,spark会对计算进行优化后再执行。
2. RDD操作
1. 创建RDD
spark提供了两种创建RDD的方式:读取外部数据结构;在驱动器程序中对一个集合进行并行化。
例子:把程序中一个已有的集合传给SparkContext的parallelize()方法
1 | lines = sc.parallelize(["panadas", "i like pandas"]) |
2. RDD操作
- 转化操作 : 返回一个新的RDD操作,但并不触发实际的计算,比如map(), filter(),union()。转化操作可以操作任意数量的输入RDD。spark会用谱系图来记录这些不同RDD之间的依赖关系。
- 行动操作 : 将最终求得的结果返回到驱动器程序,或者写入外部存储系统中。他会强制执行哪些求值过程中必须用到的RDD转化操作。
3. 传递函数
spark大部分转化操作和一部分行动操作,都需要依赖用户传递的函数来计算。
Python :
(1)传递lambda表达式:word = rdd.filter(lambda s: “error” in s)
(2)传递顶层函数或局部函数:
1 | def containsError(s): |
传递函数的过程中,python可能会将函数所在的对象也序列化传出去。当你传递的对象是某个对象的成员,或者包含对某个对象中的一个字段的引用时,spark就会把整个对象发送到工作节点上。如果传递的类里包含python不知道如何序列化传输的对象,也会导致程序失败。
替代方案是记住,传输rdd的函数引用的应该都是 局部变量 。
Java :
函数需要实现spark的org.apache.spark.api.java.function包中的任意函数接口对象来传递。这时候需要maven来建立包依赖。
标准Java函数接口:
| 函数名 | 实现的方法 | 用途 |
|---|---|---|
| Function<T, R> | R call(T) | 接收一个输入值并返回一个输出值,类似于map()和filter() |
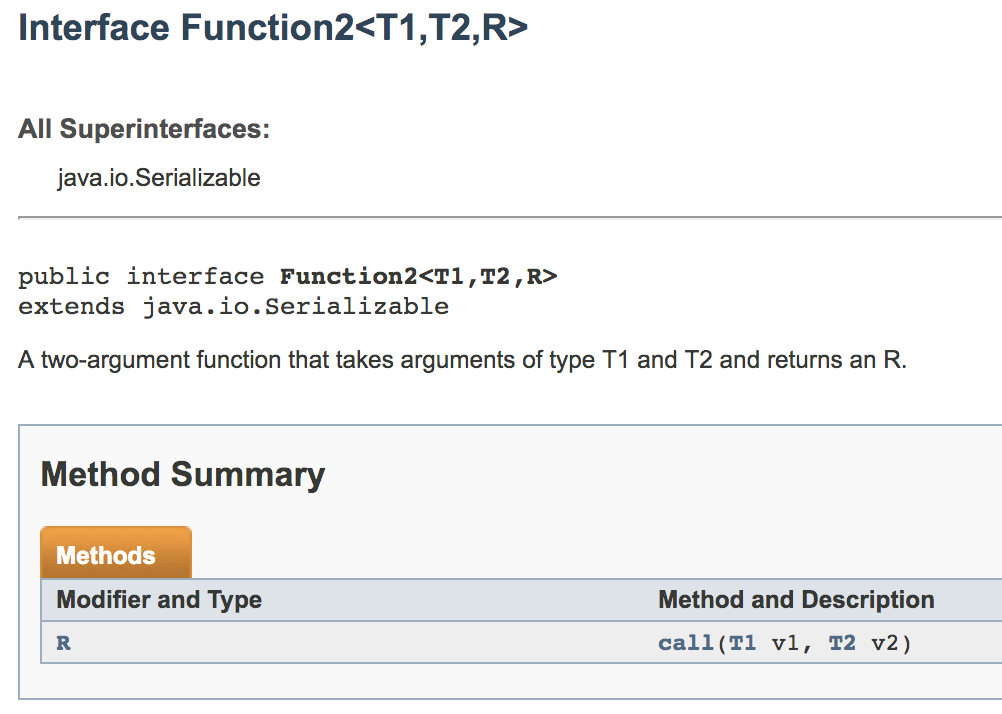
| Function<T1, T2, R> | R call(T1, T2) | 接收两个输入值并返回一个输出值,类似于aggregate()和fold()操作 |
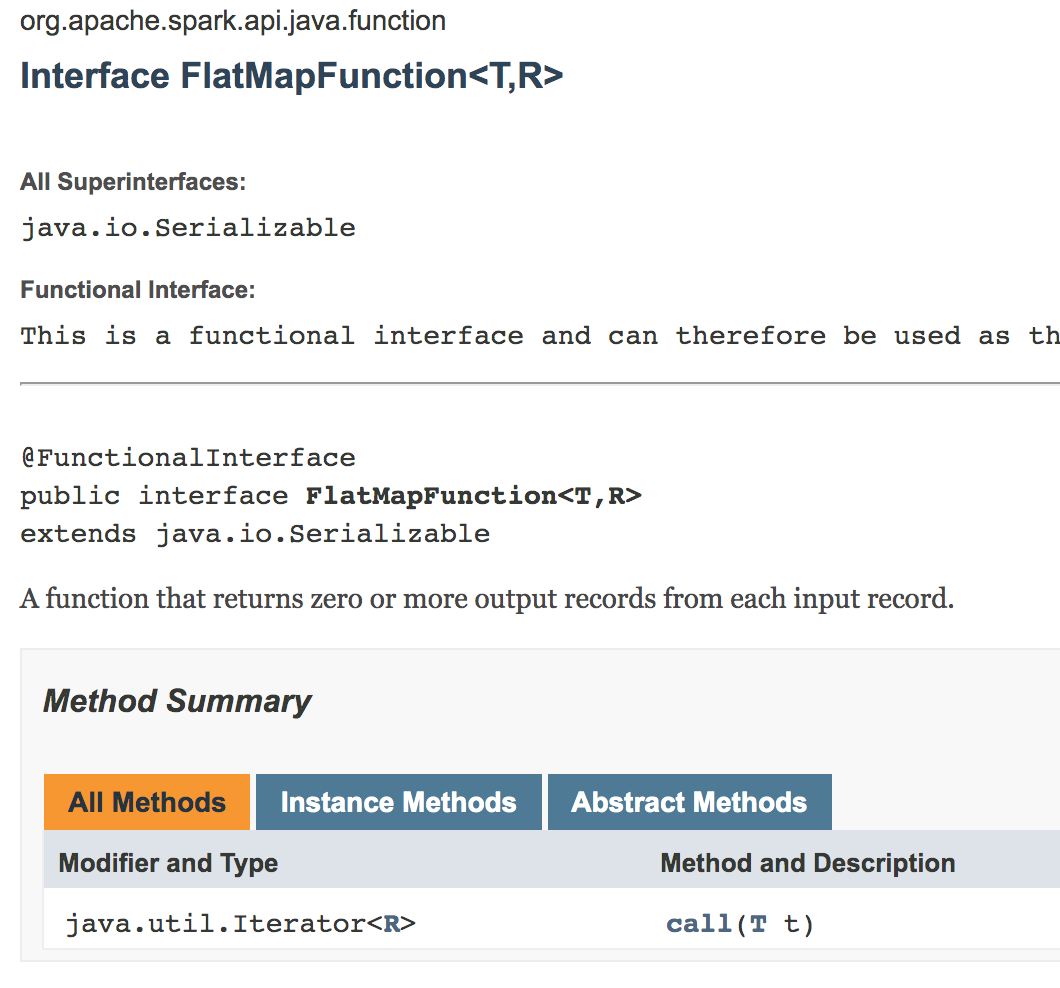
| FlatMapFunction<T, R> | Iterable |
接收一个输入值并返回任一个输出,用于类似flatMap()这样的操作 |
可以把函数类内联定义为匿名内部类,也可以创建一个具名类。
在Java8中也可以使用lambda表达式进行基本函数传递。
RDD
4. 常见的转化操作和行动操作
Tips:
所有的传入函数function<T, K, V>之类的,放在前边的都是输入类型,放在后边的都是输出类型。
基本RDD转化操作 :
(1)针对各个元素的转化操作:map()和filter()。
有时候我们希望每个输入元素生成多个输出元素,flatMap()。flatMap()函数分别应用到了输入RDD的每个元素上,不过返回的不是一个元素,而是一个返回值序列的迭代器。
注意,我们使用的是spark-2.4,这里的call函数返回值已经改成了Iterator
1 | Spark-2.4 API |
1 | //切分单词 |
Tips:
Java 中Iterable和Iterator的区别:
Iterable接口是java集合框架的顶级接口,实现此接口使集合对象可以通过迭代器遍历自身元素,我们可以看下它的成员方法:
- 返回Iterator
方法iterator() 返回一个内部元素为T的迭代器 - 返回void 方法forEach() 对内部元素进行遍历
- 返回Spliterator
方法spliterator() 返回一个可分割迭代器
我们常用的Collection, List, Set等都是Iterable的子类。可以通过.iterator()返回该类型的迭代器。
而Iterator接口就只是单向移动的迭代器,创建它的代价比较小。
(2)伪集合操作
尽管RDD本身不是严格意义上的集合,但它也支持许多数学上的集合操作,比如合并和相交操作。注意这些操作都要求操作的RDD是相同数据类型的。
RDD中最常确实的集合属性是元素的唯一性,因为常常有重复的元素。
RDD.distinct()转化操作来生成一个只包含不同元素的新RDD。不过distinct()操作的开销很大,需要将所有数据通过网络混洗。
RDD.intersection(other)转化操作来返回两个RDD中都有的元素。需要混洗
RDD.subtract(other)接收另一个RDD作为参数,返回一个由只存在第一个RDD中而不存在与第二个RDD中的所有元素组成的RDD。需要混洗
RDD.cartesian(other)计算两个RDD的笛卡尔积。返回一个矩阵。
基本RDD行动操作 :
- reduce()操作,接收一个函数为参数,这个函数操作两个相同类型的RDD并返回一个同样类型的新元素。依然通过传入function来进行相应的reduce操作。
- fold()和reduce()类似,接收一个与reduce()接收函数签名相同的函数,再加上一个初始值作为每个分区第一次调用的结果。
1 | wordcount reduce操作 |
- aggregate() 累加器。 提供一个我们期待返回的类型的初始值,然后通过一个函数将RDD中的元素合并起来放入累加器。
JavaRDD.aggregate(zeroValue, seqOp, combOp)聚合操作
@param zeroValue the initial value for the accumulated result of each partition for the
seqOpoperator, and also the initial value for the combine results from different partitions for thecombOpoperator - this will typically be the neutral element (e.g.Nilfor list concatenation or0for summation)- @param seqOp an operator used to accumulate results within a partition
- @param combOp an associative operator used to combine results from different partitions
zeroValue就是初始值,之后的聚合操作都是在这个初始值上进行操作
seqOp先在分区上进行聚合操作
combOp将不同分区上的聚合结果进行总聚合
1 | class AvgCount implements Serializable{ //创建一个可序列化对象 |
常见的对RDD的行动操作 :
| 函数名 | 目的 | 示例scala |
|---|---|---|
| collect() | 返回RDD中的所有元素 | rdd.collect() |
| count() | 返回RDD中所有元素的个数 | rdd.count() |
| countByValue() | 各元素在RDD中出现的次数 | rdd.countByValue() |
| take() | 从RDD中返回num个元素 | rdd.take(2) |
| top() | 返回RDD中最前面的num个元素 | rdd.top(2) |
| takeOrdered(num)(ordering) | 返回RDD按提供的顺序返回最前面的num个元素 | rdd.takeOrdered(2)(myordering) |
| reduce(func) | 并行整合rdd所有的数据 | |
| fold(zero)(cunf) | 和reduce()一样,但要提供初始值 | rdd.fold(0)((x, y) => x+y) |
| aggregate(zeroValue)(seqOp, combOp) | 和reduce()类似,但是通常返回不同的数据类型 | rdd.aggregate((0,0))((x, y) => (x._1+y, x._2+1), (x, y) => (x._1 + y._1, x._2 + y._2)) |
| foreach(func) | 对RDD中的每个元素使用给定的函数 | rdd.foreach(func) |
5. 在不同的RDD类型间转化
有些函数只能用于特定类型的RDD,比如mean()和variance()只能用于数值RDD上,而join()只能用在键值对RDD上。在Scala或者Java中,这些函数都没有定义在标准的RDD类中,要访问这些附加功能,必须确保获得了正确的专用RDD类。
在Java中有两个专门的类JavaDoubleRDD和JavaPairRDD来处理特殊类型的RDD。
6. RDD持久化(缓存)
如果我们希望能多次使用同一个RDD,并且避免多次计算同一个RDD,可以让spark对数据进行持久化。当让spark持久化存储一个RDD时,计算出RDD的阶段会分别保存他们所求出的分区数据。如果一个有持久化数据的节点发生故障,spark会在需要用到缓存数据时重新计算丢失的数据分区。
默认情况下,persist()会把数据以序列化的形式缓存在JVM的堆空间中。