- Spark环境搭建
- Spark shell运行
- Spark wordcount Java版
1. Spark环境搭建
spark仍然是一个解压安装包,将spark解压到固定路径,然后在环境变量中添加就可以了。
Spark带有交互式的shell可以用作即时数据分析。与其他操作系统的shell不同的是,spark的shell可以用来与分布式存储在许多机器的内存或者硬盘上的数据进行交互,并且处理过程的分发由spark自动控制完成。
注意要启动spark-shell的话,需要scala。直接brew install scala就可以了。命令:spark-shell
如果要启动python-shell的话,命令:pyspark
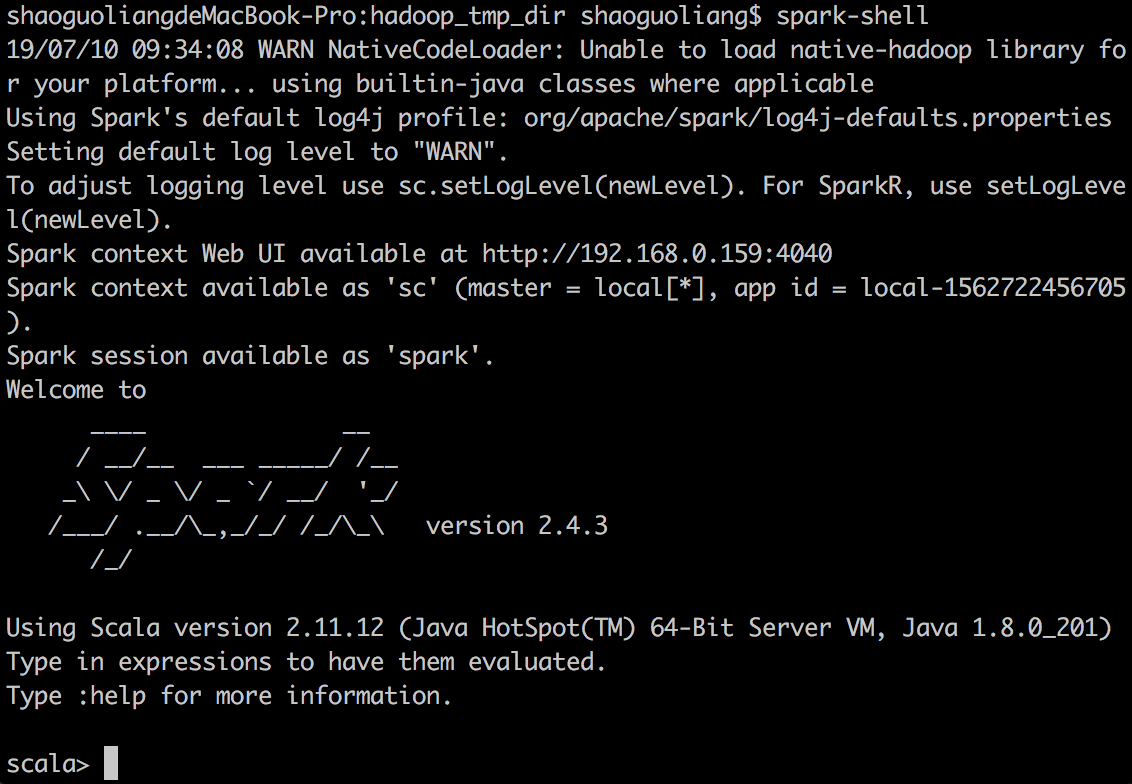
2. Spark编程基础-shell
我们在shell中采用python语言来进行spark测试
环境:
Hadoop环境配置为单机模式,hadoop.tmp.dir设置为了一个文件夹。
打开pyspark后,进行行数统计:
注意这个文件TEST_SPARK.md是需要存在于hadoop.tmp.dir中的。但是这个时候我并没有启动hadoop,所以不知道是不是这么设置了之后就默认会从这个路径来读取了。
1 | >>> lines = sc.textFile("TEST_SPARK.md") #创建一个名为lines的RDD |
Spark程序核心概念
从上层来看,每个spark应用都由一个驱动器程序driver program来发起集群上的各种并行操作。驱动器程序包含应用的main函数,并且定义了集群上的分布式数据集,还对这些分布式数据集应用了相关操作。在shell中,实际的驱动器程序就是spark shell本身。
驱动器程序通过一个SparkContext对象来访问Spark。这个对象代表对计算集群的一个连接。
Spark API
Spark可以在Java,python,scala的独立程序中被连接使用,接下来使用的API就一样了。
在java和scala中,是需要给应用添加一个对spark-core的maven依赖就可以了。对应于安装的spark-2.4.3来说,使用如下的依赖:
1 | <!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core --> |
3. Spark wordcount Java版程序
(1)Spark java程序
自从Java8之后,java支持了’->‘ 这个简写语法,但是要在maven编译中添加限定。这个spark传递函数将会在后续进行学习。
按照《Spark快速大数据分析》中第二章的wordcount例程出现了Iterator和Iterable转换的不匹配。既然Java8支持了lambda简写,很明确,那就大势所趋还是使用lambda简写吧。
1 | /** |
注意:
相关的文件读取I/O一定要注意,
路径名前缀为:file:// 表示是从本地主机读取和写入文件
路径名前缀为:hdfs:// 表示是从集群中读取和写入文件
上述代码中就没有写清楚从哪里读取textFile,也没有写清楚textFile写到哪里,注意一定是要全路径名。
正确的写法是:
1 | JavaRDD<String> input = sc.textFile("file:///Users/shaoguoliang/Workspaces/MyEclipse 2017 CI/spark-test-0.1/data/Test_spark.txt"); |
(2) maven 依赖:
1 | <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> |
(3)mvn编译
在Eclipse中,点击项目名称->Run as-> maven build…
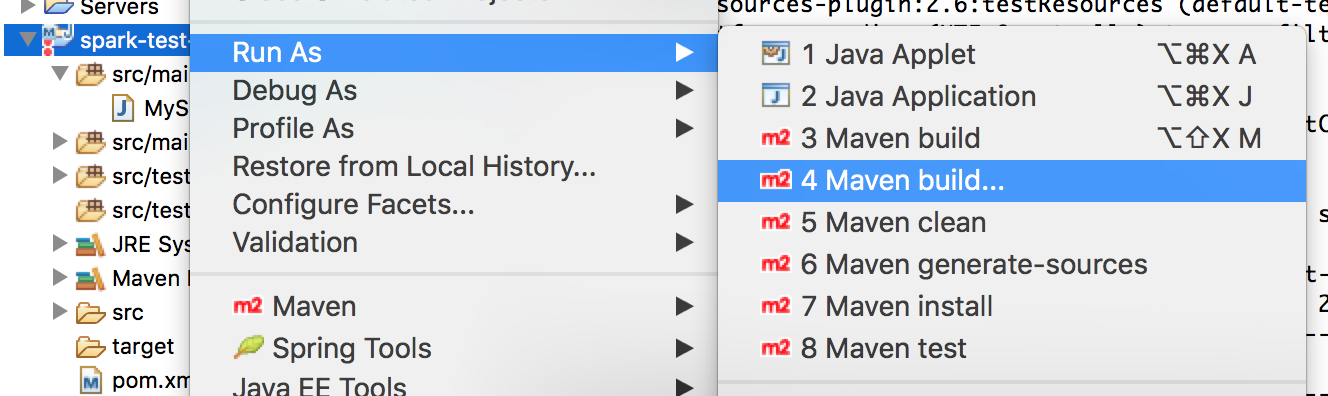
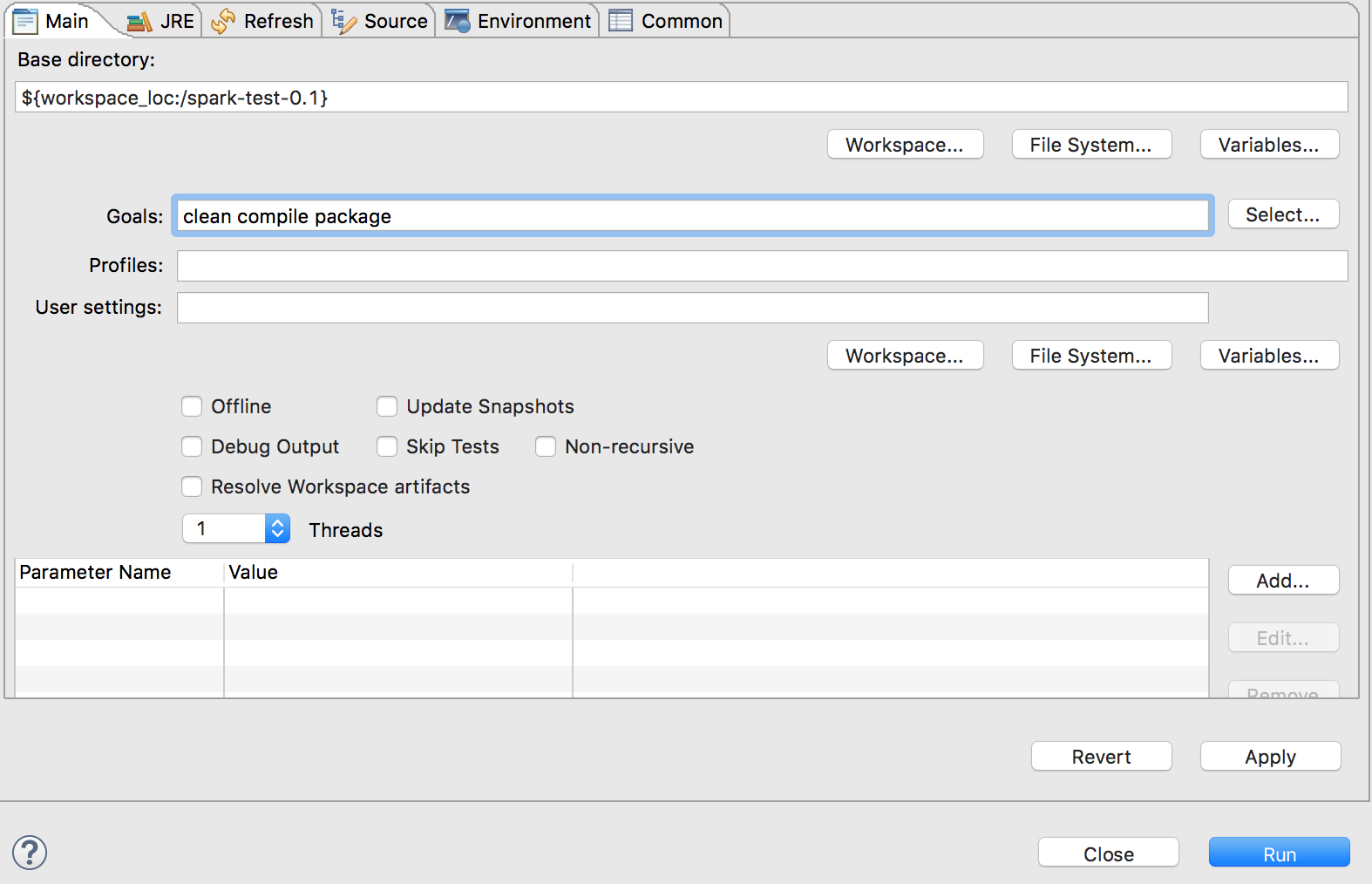
在mvn build 中的goal里添加想要执行的mvn操作
clean compile package
之后看到building jar显示已经生成了jar就可以了。
1 | [INFO] --- maven-jar-plugin:2.6:jar (default-jar) @ spark-test-0.1 --- |
(4)spark 提交
因为我们已经将 $SPARK_HOME/bin添加进了 环境变量中,因为找到jar包所在目录,运行以下命令:
1 | spark-submit --master spark://localhost:7077 ./spark-test-0.1-0.0.1-SNAPSHOT.jar |
之后将会在target目录下生成
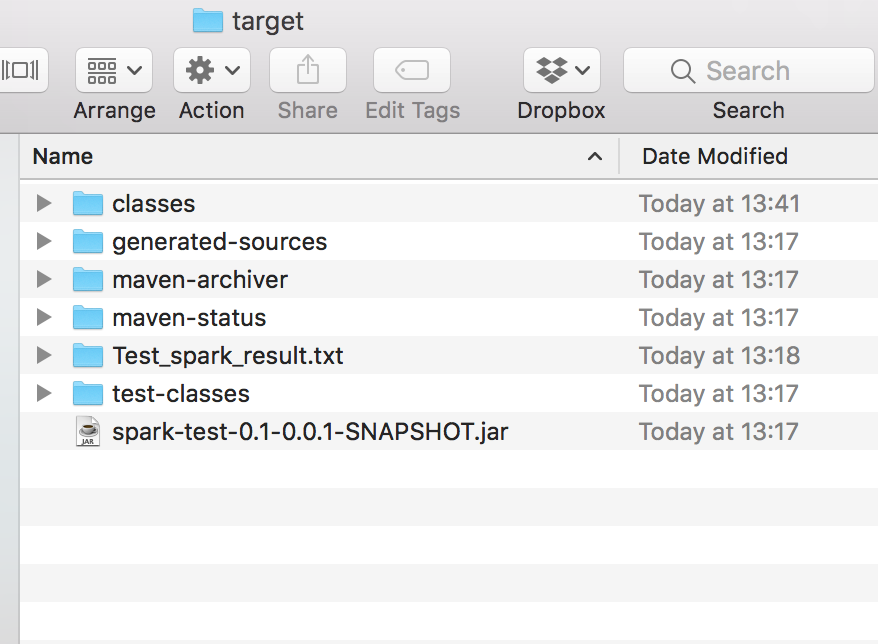
Test_spark_result.txt
将最终结果放在part-00000
注意,这里的输入文件路径和输出文件路径都是在jar包路径下的。