本文对应于《Hadoop权威指南》第6章Mapreduce应用开发的内容
通常情况下我们进行mapreduce开发要对每个模块进行单元测试,来检查模块的行为是否正确。本文主要介绍在mvn下进行mapreduce模块单元测试。
使用mvn开发mapreduce有两种方法,一个是源码编译(问题少,你必须知道你在干什么,本文采用的方法);另外一个是借助IDE进行编译(集成度高,设置自动生成,写代码可以自动补全,比较爽)。在使用MyEclipse进行mapreduce开发的过程中,出现了hadoop插件导致的问题,因此,在完全解决hadoop插件的问题之前,我选择了如下方法:
- 使用IDE进行代码编写。
- 上传到CentOS中,进行maven源码编译。
- 在这个过程中要尤其注意pom依赖。
使用MRUnit写单元测试 - v1
MRUnit是一个测试库,它便于将已知的输入传递给mapper或者检查reducer的输出是否符合预期。MRUnit与标准测试框架JUnit一起使用,可以在正常的开发环境中运行MapReduce作业测试。
1 | maven工程目录结构 |
在源文件下的main目录编写mapper模块和reducer模块。将相应的测试模块放在test目录下。注意package的目录等级。
Mapper模块
1 | package v1; |
MapperTest模块
1 | package v1; |
这个测试很简单:内置传输一个天气记录作为mapper的输入,然后检查输出是否是读入的年份和气温。
测试的是mapper,可以使用MRUnit的MapDriver.调用runTest()方法。
@Test 表示该方法可以不用通过main函数入口就可以执行得出运行结果,用于标准测试。注意被@Test修饰的方法必须是public。
.withMapper 指向被测试的Mapper,注意该Mapper需要和MapperTest处在同一个package下,这样才能找到Mapper类。
.withInput 指向输入的key和value。这里因为mapper的原始输入kay是文本的偏移值,所以没有意义,这个key可以随意设定。
.withOutput 指向期望的输出。key(1950)和期望的输出值value(-11)。如果mapper没有输出期望值,则MRUnit测试失败。
根据withOutput()被调用的次数,MapDriver能用来检查0,1或多个输出记录。
mvn编译
1. pom.xml的导入:
在pom.xml中可以引入一个通用的pom基础,如下:
其中hadoop-meta中包含了很多包版本的定义等通用信息。同时添加了用于标准单元测试的junit。注意,在创建mvn project的时候默认的junit版本是3.8.2,而这个版本在导入org.junit.*这个包的时候会报错,这个包属于junit 4版本,所以要在pom.xml中修改junit版本。
1 | <parent> |
pom母版
1 | hadoop-meta/pom.xml |
2. pom.xml需要加载的依赖包:
hadoop-client其实包含了hadoop-common依赖包,所以只用添加一个client就可以了。
mrunit要加上classifier表示是hadoop2版本下的。
1 | <dependency> |
3. MyEclipse下mvn编译报错
在MyEclipse下对上述工程进行编译会得到mvn编译报错:
1 | Running v1.MaxTempMapperTest |
这个错误并不是因为pom依赖出现问题,而是在MyEclipse下的hadoop插件出现了问题,导致依赖包导入不全。提供的解决帮助也把问题指向了hadoop-eclipse-plugin插件。这个遗留问题后期解决。TBC
4. mvn命令行编译
(1) 执行mvn test测试,测试出错: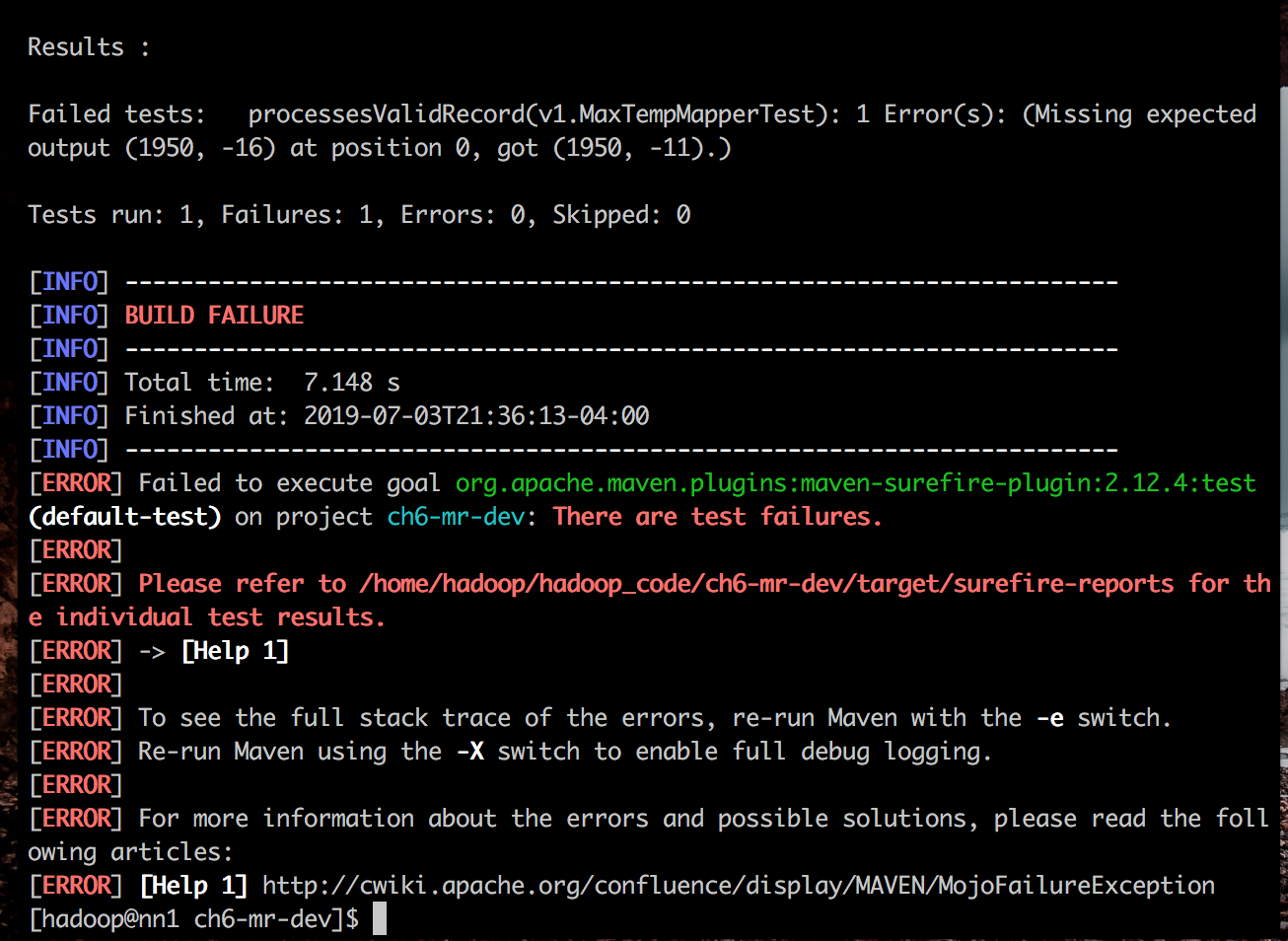
可以看到当我们把期待输出的温度调整为-16的时候,实际mapper得到的输出仍然为-11,这是测试出错,会报error。
Reducer与ReducerTest模块
注意导入库的版本问题。
如:
org.apache.hadoop.mapred.Reducer 与 org.apache.hadoop.mapreduce.Reducer
org.apache.hadoop.mrunit.ReduceDriver 与 org.apache.hadoop.mrunit.mapreduce.ReduceDriver
不注意检查经常会导致编译出错。
Reducer程序
1 | package v1; |
Reducer Test
1 | package v1; |
Tips
我是实用rz工具将代码传入centos进行mvn编译的,rz有一个问题是,如果目标路径里已经有同名的文件了,他是不会完成传输的。所以经常发现已经提交了代码实际却没有更改的问题。
在使用Eclipse进行mvn test时,报了如下几个错误:
- java.lang.NoClassDefFoundError: com/ctc/wstx/io/InputBootstrapper
- java.lang.NoClassDefFoundError: Could not initialize class org.apache.hadoop.io.Text
完全不知道这个错误是为什么会出现的。在源码mvn构建就没有任何问题,所以应该是Eclipse配置的问题。如果你知道这两个报错如何解决请联系我guoliang_shao@u.nus.edu。不胜感激