Hadoop IO接口相关操作包括:文件压缩,序列化
文件压缩
文件压缩有两大好处:减少存储文件所需要的磁盘空间,加速数据在网络和磁盘上的传输。这两大好处在处理大量数据时相当重要。
与Hadoop结合使用的常见压缩方法:
| 压缩格式 | 工具 | 算法 | 文件扩展名 | 是否可切分 |
|---|---|---|---|---|
| DEFLATE | 无 | DEFLATE | .deflate | 否 |
| gzip | gzip | DEFLATE | .gz | 否 |
| bzip2 | bzip2 | bzip2 | .bz2 | 是 |
| LZO | lzop | LZO | .lzo | 否 |
| LZ4 | 无 | LZ4 | .lz4 | 否 |
| Snappy | 无 | Snappy | .snappy | 否 |
所有的压缩算法都需要权衡_空间/时间_。压缩和解压缩的速度更快,其代价通常是只能节省少量的空间。上表中的工具提供9个不同的选项来控制空间/时间权衡:选项-1为优化压缩速度,-9为优化压缩空间。
不同的压缩工具有不同的压缩特性。其中,是否可切分对应压缩算法是否可以搜索数据流的任意位置并进一步向下读取数据。可切分压缩格式尤其适合MapReduce。
codec 压缩-解压算法的一种实现。
在Hadoop中,一个对CompressionCodec接口的实现代表一个codec。
1. 通过CompressionCodec对数据流进行压缩和解压缩。
- 对写入输出数据流的数据进行压缩createOutputStream(OutputStream out),获得CompressionOutputStream对象。
- 对输入数据流读取的数据进行解压缩,调用createInputStream(InputStream in),获得CompressionInputStream对象。
1 | Example: 压缩从标准输入读取的数据,然后将其写到标准输出 |
- 完全合格名称为第一个命令行参数。
- 使用ReflectionUtils新建一个codec实例,获得一个在System.out上支持压缩的压缩方法。
- 对IOUtils类调用copyBytes方法(这是一个静态方法)将输入数据流复制到输出压缩对象。
- 对CompressionOutputStream对象调用finish()方法,要求压缩方法完成到压缩数据流的写操作,但不关闭数据流。
2. 通过CompressionCodecFactory推断CompressionCodec
在读取一个压缩文件时,通常可以通过文件扩展名推断需要使用哪个codec。通过getCodec()方法,CompressionCodecFactory提供了一种可以将文件扩展名映射到一个CompressionCodec的方法。该方法取文件的Path对象作为参数。
可以通过调用静态方法CompressionCodecFactory.removeSuffix来直接生成当前目录下输出文件名。
3. CodecPool。如果使用原生代码库并需要在应用中执行大量的压缩和解压缩操作,可以考虑使用CodecPool。
4. 压缩和输入分片。
在考虑如何压缩将有MapReduce处理的数据时,理解压缩格式是否支持切分(splitting)十分重要。以一个存储在HDFS文件系统中且压缩前大小为1GB的文件为例。如果HDFS块大小设置为128MB,那么该文件将被存储在8个块中。把这个文件作为输入数据的MapReduce作业,将创建8个输入分片,其中每个分片作为一个单独的map任务输入被单独处理。
如果文件是gzip压缩的,压缩后大小为1GB,HDFS将这个文件保存为8个数据块。但将每个数据块单独作为一个输入分片是无法实现独立的map工作的,因为不支持splitting。这种情况下,mapreduce不会切分gzip压缩文件,而是使用一个map任务来处理8个HDFS数据块。这牺牲了数据的本地性,因为大多数块并没有存储在执行该map任务的节点上。并且map任务数越少,作业的粒度就越大,运行时间可能会更长。
bzip2文件提供不同数据块之间的同步标识,因而它支持切分。
在MapReduce中使用压缩
如果输入文件是压缩的,那么在根据文件扩展名推断出相应的codec后,MapReduce会在读取文件时自动解压缩文件。
要想压缩MapReduce作业的输出,应在作业配置过程中将mapreduce.output.fileoutputformat.compress属性设为true,将mapreduce.output.fileoutputformat.compress.codec属性设置为打算使用的压缩codec的类名。
1 | FileOutputFormat.setCompressOutput(job, true); |
MapReduce应用读、写的是未经压缩的数据,但如果对map阶段的中间输入进行压缩,也可以获得不少好处。由于map任务的输出需要写到磁盘并通过网络传输到reducer节点,所以通过使用LZO、LZ4或者Snappy这样的快速压缩方式,是可以获得性能提升的,因为需要传输的数据减少了。
序列化
序列化(serialization)是指将结构化对象转化为字节流以便在网络上传输或写到磁盘进行永久存储的过程。反序列化(deserialization)是指将字节流转回结构化对象的逆过程。
序列化用于分布式数据处理的两大领域:进程间通信和永久存储。
在Hadoop中,系统中多个节点上进程间的通信是通过“远程过程调用RPC”实现的。RPC协议将消息序列化成二进制流后发送到远程节点,远程节点接着讲二进制流反系列化成原始消息。RPC序列化格式的理想属性为:紧凑;快速;可扩展;支持互操作。
Hadoop使用的是自己的序列化格式Writable,绝对紧凑,速度快,但不容易用Java意外的语言进行扩展或使用。Writable是Hadoop的核心(大多数的MapReduce程序都会在key,value类型使用它)。
Writable接口
Writable接口定义了两个方法,一个将其状态写入DataOutput二进制流,另一个从DataInput二进制流读取状态;
1 | import java.io.DataOutput; |
WritablComparable接口和comparator。该接口允许实现直接比较数据流中的记录,无须先把数据流反序列化为对象,这样避免了新建对象的额外开销。
1. Java基本类型的Writable封装器
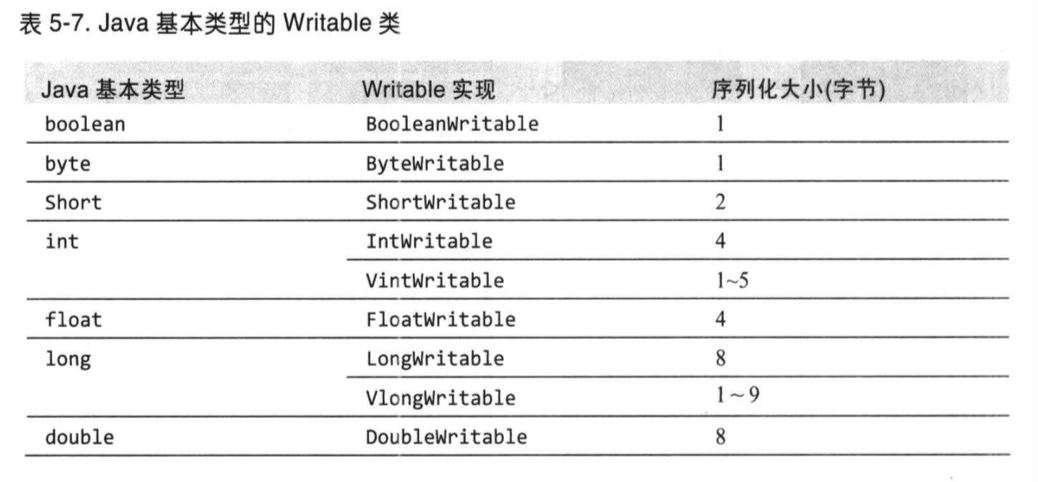
所有的封装包含get()和set()两个方法用于读取和存储封装的值。
对整数进行编码时,有两种选择,_定长格式和变长格式_,如果编码的数值相当小(-127到127)之间,边长格式就只用一个字节进行编码,否则,使用第一个字节来表示数值的正负和后边跟多少个字节。
例如 VIntWritable(163) 会编码成“8fa3” a=10*16, 3=3*1。
2. Text类型
Text是针对UTF-8序列的Writable类。一般可以认为他是java.lang.String的Writable等价。
Text类使用整形来存储字符串编码中所需要的字节数,因为最大值为2GB。
Text.charAt()方法返回的是一个表示Unicode编码位置的int类型,而String返回的是一个char类型值。
Text.find()方法,类似于String的indexOf()方法。
3. BytesWritable类型
是对二进制数据数组的封装。它的序列化格式为一个指定所含数据字节数的整数域(4个字节),后跟数据内容本身。
例如:长度为2的字节数组包含3和5。序列化形式为一个4字节整数(00000002)和两个字节(03和05)。
4. NullWritable类型
特殊类型,序列化长度为0。它并不从数据流中读取数据也不写入数据。充当占位符。在MapReduce中,如果不需要使用key或value的序列化地址,就可以将key或value的值声明为NullWritable,这样可以高效存储常量空值。
5. ObjectWritable和GenericWritable
ObjectWritable是Java基本类型的通用封装。它在Hadoop RPC中用于对方法的参数和返回类型进行封装和解封装。
如果封装的类型数量比较少并且能够提前知道,那么可以通过使用静态类型的数组,并使用对序列化后的类型的引用加入位置索引来提高性能。GenericWritable就是这种方式。
6. Writable集合类。
ArrayWritable,ArrayPrimitiveWritable,TwoDArrayWritable,MapWritable,SortedMapWritable以及EnumMapWritable。