MapReduce程序
参考《Hadoop权威指南》,依旧是MapReduce基本框架。
在NCDC记录中每一行是一条数据记录,每一行不同的偏移量代表不同的内容。
Map 程序
1 | package com.fredshao.hadoop; |
Reduce程序
1 | package com.fredshao.hadoop; |
Main函数 Job
1 | package com.fredshao.hadoop; |
使用maven进行编译
可参考 Maven是什么
构建maven project
首先确认已经安装解压maven,并在环境变量/etc/profile中配置 $MAVEN_HOME/bin
1
2
3
4在预计工程目录下命令行, 注意版本不同。我使用maven 3.6.1, 命令中是generate而不是create
mvn archetype:generate -DgroupId=com.fredshao.hadoop -DartifactId=MinTemp
这条命令会生成pom.xml配置文件和src下根据groupId创建的包结构。而且并不用向上述博客中设置-DarchetypeArtifactId。生成project后,将源代码放入src相应目录下。
配置pom.xml文件导入依赖包。
从代码编写过程中我们知道我们需要hadoop-common,hadoop-hdfs,hadoop-client三个包。
pom.xml (1)mvn包创建完成的时候
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.fredshao.hadoop</groupId>
<artifactId>MinTemp</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<!--maven包使用规范:
groupid和artifactId被统称为“坐标”是为了保证项目唯一性而提出的,
如果你要把你项目弄到maven本地仓库去,你想要找到你的项目就必须根据这两个id去查找。
(1)虽然产生的项目结构文件与groupId无关,但是大家公认的规范是填写项目包名;
(2)artifactId填写你负责的模块名,如项目名-模块名
--!>
<name>MinTemp</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
</dependencies>
</project>pom.xml (2)导入项目依赖包 添加如下:注意版本号
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.9.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.9.2</version>
</dependency>当你建立一个 Maven 的项目,Maven 会检查你的 pom.xml 文件,以确定哪些依赖下载。首先,Maven 将从本地资源库获得 Maven 的本地资源库依赖资源,如果没有找到,然后把它会从默认的 Maven 中央存储库 – http://repo1.maven.org/maven2/ 查找下载。在Maven中,当你声明的库不存在于本地存储库中,也没有不存在于Maven中心储存库,该过程将停止并将错误消息输出到 Maven 控制台。 因此在maven编译的过程中要保持网络连接,在国内最好配置阿里云镜像。
mvn 编译
在pom.xml路径下使用命令mvn clean compile进行编译。该命令将忽略之前生成的所有编译文件,重新生成编译文件进行覆盖。生成target/classes/目录下所有的编译.class文件
mvn 打包生成jar
命令mvn package对生成的所有文件进行打包。会在target/目录下创建.jar文件
使用hadoop jar执行
1 | $hadoop/bin hadoop jar ~/.../target/MinTemp-1.0-SNAPSHOT.jar /input_ncdc /output_ncdc |
以上两个错误出现的问题都是RunJar.main方法找不到该jar包的主函数。
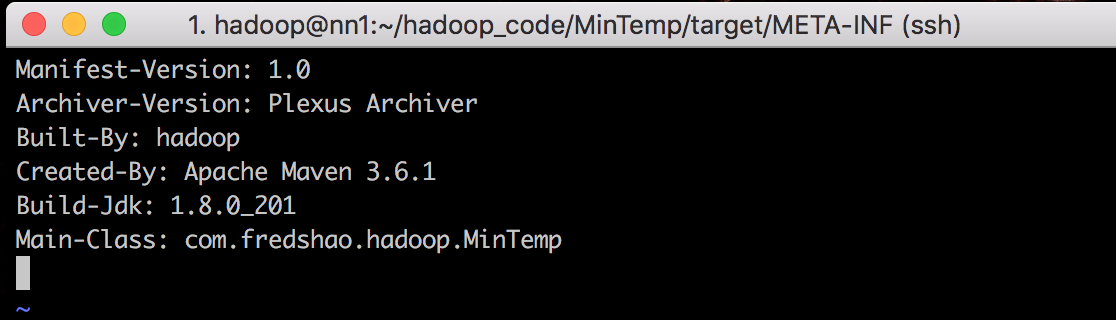
解压jar包 jar xvf MinTemp-1.0-SNAPSHOT.jar, 找到MANIFEST.MF文件
1 | Manifest-Version: 1.0 |
该jar包没有显示class-path,没有显示主函数。这些需要在mvn编译的时候进行控制
修改pom.xml,添加主函数入口
1 | 添加主函数入口 |
继续进行编译和打包。
hadoop jar运行
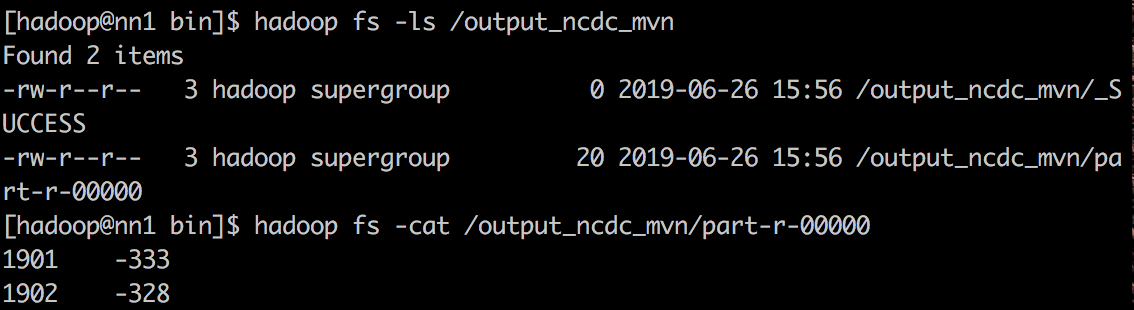
1 | hadoop jar ~/hadoop_code/MinTemp/target/MinTemp-1.0-SNAPSHOT.jar /input_ncdc /output_ncdc_mvn |
然后运行成功。
jar包解压
运行结果