基本要求
- 完成Hadoop配置,参考https://floodshao.github.io/posts/hadoop_zookeeper_hbase_setup
- MapReduce基本了解。
MapReduce基础
- MapReduce任务过程分为两个处理阶段:map阶段和reduce阶段。每个阶段都以key-value作为输入输出,其类型由程序员来选择。需要写两个函数:map函数和reduce函数。
- map阶段输入原始数据。注意这里的原始数据指的是最原始的记录文本数据。一般将原始数据的每一行作为文本输入。key为某一行起始位置相对于文件起始位置的偏移量,但这个信息我们不需要。(在hadoop权威指南里,NCDC数据每一行是一条数据;在wordcount里就是一行文本,包含多个单词)
- map函数的输出依然是key-value经MapReduce框架处理(combine)后,最后发送到reduce函数。这个combine处理是对key-value进行排序和分组。
- reduce函数对输入的key-value进行相应的处理,得到我们想要的结果(在wordcount中就是统计每个单词出现的个数)
1 | MapReduce 流程: |
在编写的过程中,我们实际只需要写Mapper.map()和Reducer.reduce()方法。
自定义map和reduce
1. map方法
Mapper源代码查看:
源码路径/hadoop-2.9.2-src/hadoop-mapreduce-project/hadoop-mapreduce-client/hadoop-mapreduce-client-core/
package org.apache.hadoop.mapreduce
在TokenizerMapper.java中继承Mapper类重写Mapper.map()方法。
Mapper产生一个intermediate pairs,输入输出类型并不要求一致。
The Hadoop Map-Reduce framework spawns one map task for each {@link InputSplit} generated by the {@link InputFormat} for the job. Mapper implementations can access the {@link Configuration} for the job via the {@link JobContext#getConfiguration()}.
%TokenizerMapper.java
package com.fredshao.hadoop;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
public class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{
IntWritable one = new IntWritable(1);
Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException{
StringTokenizer itr new StringTokenizer(value.toString());
while(itr.hasMoreTokens()){
word.set(itr.nextToken());
context.write(word, one);
}
}
}2. reduce方法
Reducer源代码查看:
源码路径/hadoop-2.9.2-src/hadoop-mapreduce-project/hadoop-mapreduce-client/hadoop-mapreduce-client-core/
package org.apache.hadoop.mapreduce
在IntSumReducer.java中继承Reducer并重写Reducer.reduce()方法。
%IntSumReducer.java
package com.fredshao.hadoop;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
public class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable>{
IntWritable result = new IntWritable();
//这里Text key是输入键,Iterable是经过combine的输入值list
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException{
int sum = 0;
for(IntWritable val:values){
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}3. main函数,建立mapreduce执行入口
MapReduce中job的使用。MapReduce.Job类
It allows the user to configure the job, submit it, control its execution, and query the state. The set methods only work until the job is submitted, afterwards they will throw an IllegalStateException. 在mapreduce执行前对job进行设定。
job类一般的配置:
建立新的job:
- Job job = Job.getInstance();
- job.setJarByClass(MyJob.class); //程序入口
设定job相关参数
- job.setJobName(“myjob”);
- job.setInputPath(new Path(“in”));
- job.setOutputPath(new Path(“out”));
- job.setMapperClass(MyJob.MyMapper.class);
- job.setReducerClass(MyJob.MyReducer.class);
提交job,submit the job
- job.waitForCompletion(true);
1 | %WordCount.java |
程序打包流程
将上述mapreduce包含的3个程序进行打包:
编译需要的hadoop jar包:
Hadoop 2.x 版本中jar不再集中在一个 hadoop-core-*.jar 中,而是分成多个 jar。
1
2
3
4
5
6$HADOOP_HOME/share/hadoop/common/hadoop-common-2.4.1.jar
$HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.4.1.jar
$HADOOP_HOME/share/hadoop/common/lib/commons-cli-1.2.jar
从上述import,io,fs和util来自common,mapreduce来自mapreduce-client-core.
commons-cli-1.2.jar是跟maven编译相关的jar包,目前不知道有什么作用。使用javac进行编译
1
javac -classpath /path1:/path2:/path3 -d classes/ src/*.java
注意事项:
- 如果使用myeclipse进行开发的话,那么如果编写不报错,会自动在相同目录下生成bin文件夹,里边是编译好的class。直接使用就好了
- -d 是生成的class文件的地址
- -classpath是源代码中依赖库的路径,用:隔开
将class打包成jar
1
jar -cvf WordCount.java classes
classes是需要打包的所有编译成功的类的目录地址
MapReduce执行
1. hadoop环境启动:
在这里,与之前在https://floodshao.github.io/posts/hadoop_zookeeper_hbase_setup的配置有些不同。
core-site.xml中:master和slave中配置相同
<name>fs.defaultFS</name> <value>hdfs://nn1.hadop:9000</value>hdfs-site.xml中:
<property> <name>dfs.name.dir</name> <value>/home/hadoop/hadoop/name</value> </property> <property> <name>dfs.data.dir</name> <value>/home/hadoop/hadoop/data</value> </property>
成功启动hadoop集群的标志是: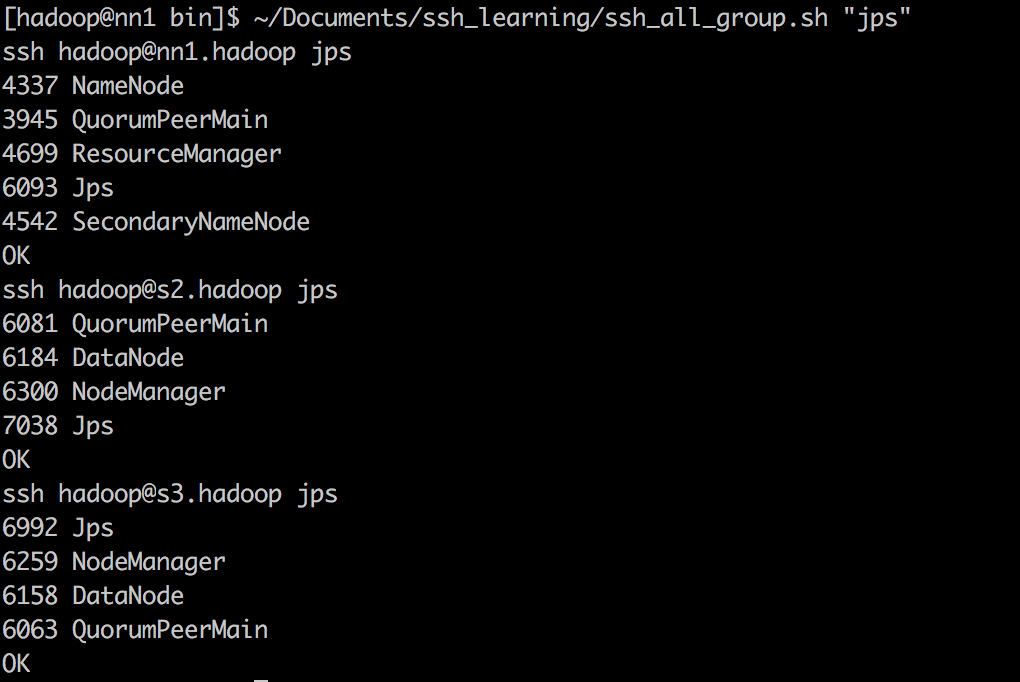
在启动集群的过程中,出现了namenode无法启动,datanode无法启动,以及下图中出现的完全没有分配存储空间的问题: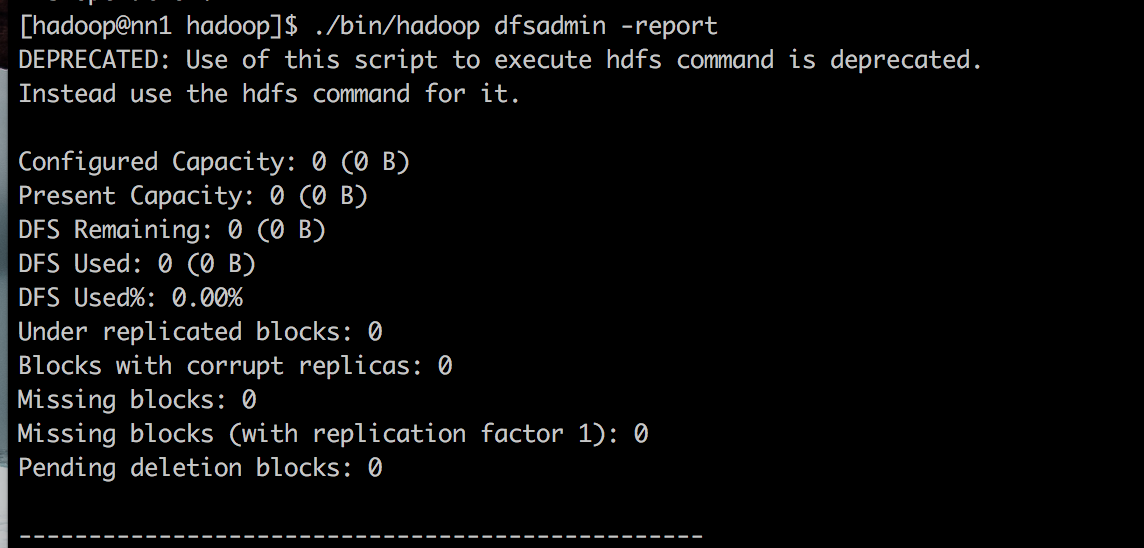
采取的措施如下:
- 查看netstat -tlpn,master是否在监听nn1.hadoop:9000端口。基本上出现上述问题都是看不到。因为hadoop集群启动成功一定会自动监听9000端口
- 将hdfs-site中的name.dir和data.dir所指向的物理位置全部删除
- 将/hadoop/logs全部删除
- 重新初始化hadoop namenode -format
- 注意不要多次重复初始化namenode,这样很容易继续导致上述问题
- 然后再次进行hadoop集群初始化
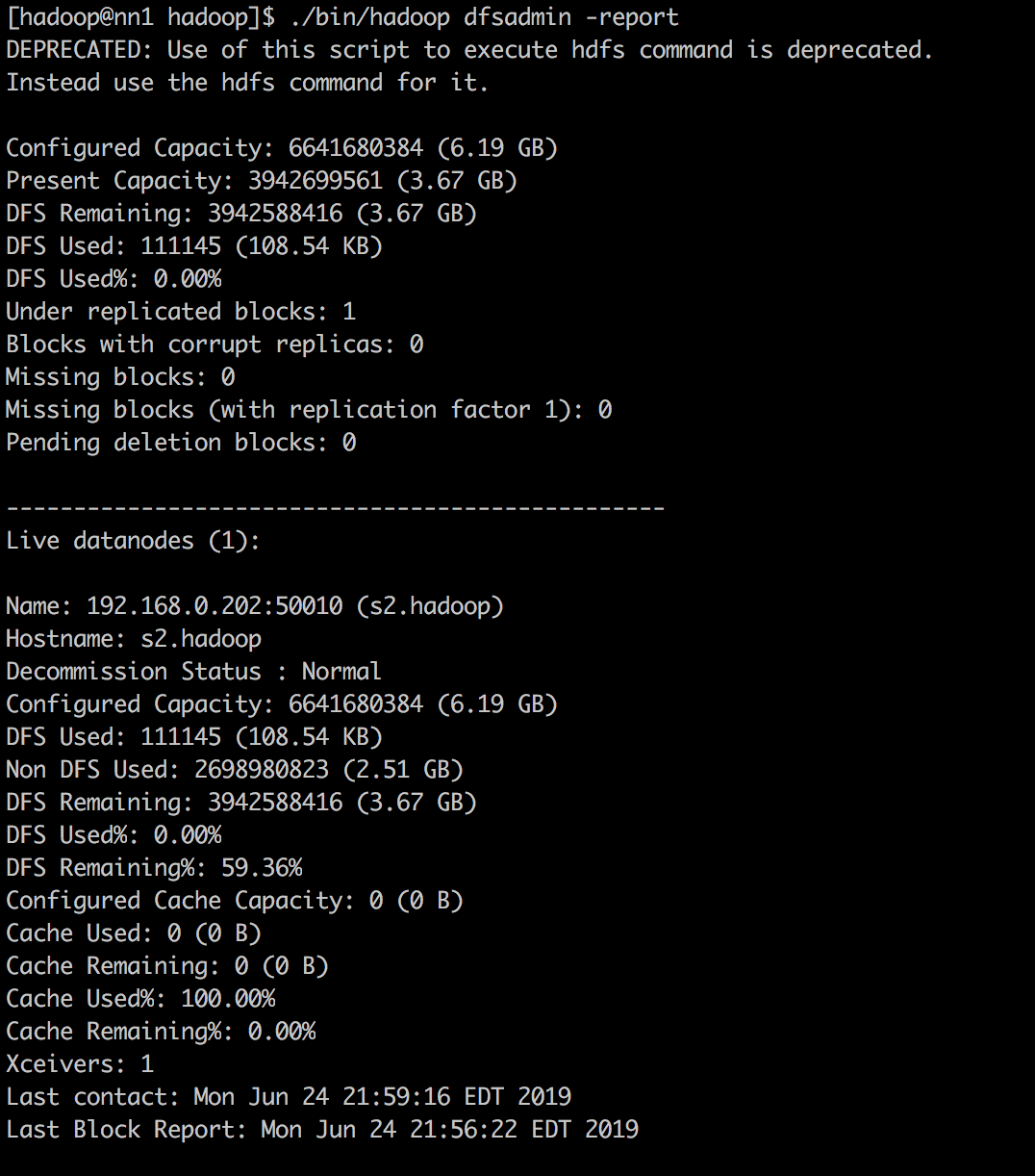
2. 执行:
注意mapreduce处理的文件必须是hdfs部署下的文件。
先查看hdfs相关操作:$HADOOP_HOME/bin/
hadoop fs -ls / #hdfs根目录ls
hadoop fs -put [本地文件files] [hdfs文件/input] #将files放入input中
3. 执行wordcount:
注意要带上package信息,因为在程序中添加了package信息。jar参数表示指定jar包的位置,主类为com.fredshao.hadoop.WordCount。运行程序处理/input目录下的文件,将结果写入/output。
1 | $ hadoop/bin/hadoop jar wordcount/WordCount.jar com.fredshao.hadoop.WordCount /input /output |

4. 查看运行结果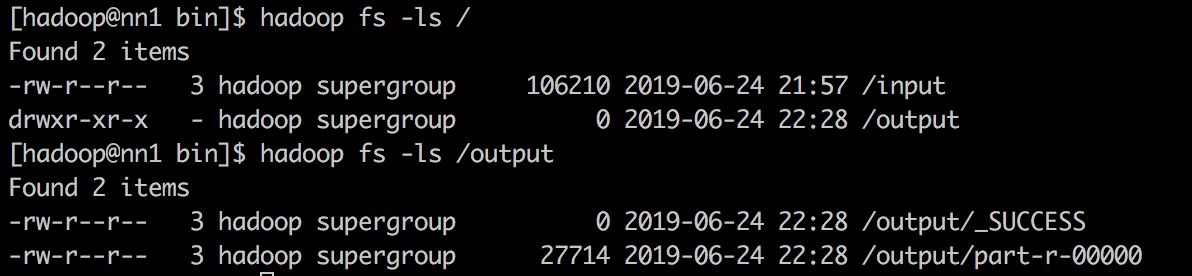
在/output目录下有两个文件,结果就存放在/output/part-r-00000中。