Hadoop + ZooKeeper + HBase 分布式集群搭建
参考:https://blog.csdn.net/lisonglisonglisong/article/details/46974723
搭建说明
Hadoop是分布式操作系统(基础是hdfs文件系统,和yarn环境资源协调服务),ZooKeeper是分布式应用程序协调服务,HBase是分布式面向列的开源数据库。
环境搭建说明:
- 集群环境至少需要3个节点(也就是3台服务器设备):1个Master,2个Slave,节点之间局域网连接,可以相互ping通
- 三个节点均使用CentOS7操作系统,为便于维护和批量操作,在3个节点上的集群环境配置使用相同的路径。具体配置路径如下:
- hadoop: /usr/local/hadoop
- zookeeper: /usr/local/zookeeper
- hbase: /usr/local/hbase
- 三个节点使用hadoop用户进行相关集群操作,上述配置路径的用户组全部要设为hadoop:hadoop
1
chown -R hadoop:hadoop /usr/local/hadoop
三个节点的ip设置
在/etc/hosts中设置如下ip地址hostname ip user role nn1.hadoop 192.168.0.204 hadoop master s2.hadoop 192.168.0.202 hadoop slave s3.hadoop 192.168.0.203 hadoop slave
设置三个用户的ssh免密登录:可参考https://floodshao.github.io/posts/ssh_remote_access
1
2
3
4
5
6
7
8
9
10
11
(1) 在.ssh下id_rsa私钥和id_rsa.pub公钥
hadoop#~/.ssh ssh-keygen -t rsa
(2) 客户端为A,服务端为B,A与B免密沟通要将A的公钥放在B的authorized_keys中。例如,在s2服务器上:
hadoop#~/.ssh scp -p id_rsa.pub hadoop@nn1.hadoop:~/.ssh/authorized_keys
(3) 登录B端验证:
ssh hadoop@nn1.hadoop
关闭服务器的防火墙:zookeeper在维护服务器间通信时可能会因为防火墙的存在而导致维护失败。一般会关闭防火墙。
1
2
3
4
5centos 7关闭防火墙命令:
查看防火墙状态:systemctl status firewalld.service
执行关闭命令:systemctl stop firewalld.service
执行开启命令:systemctl start firewalld.service
执行开机禁止防火墙启动命令:systemctl disable firewalld.service环境搭建准备:
- java环境
- /etc/hosts在三个节点上同时配置节点映射
- 集群之间建立免密ssh连接:master到slave,slave到master,slave之间不必进行免密ssh认证
- hadoop编译安装(master上)
- zookeeper解压安装(master上)
- hbase解压安装(master上)
Hadoop环境配置 /usr/local/hadoop 用户属hadoop:hadoop
将Hadoop配置为全分布模式,参考《Hadoop权威指南》第十章。
环境配置文件位于/etc/,相关配置文件解释。
| File Name | Description | Format | Remark |
|---|---|---|---|
| hadoop-env.sh | 运行hadoop的环境变量 | Bash | 默认JAVA_HOME要转换为绝对路径,否则会在启动hadoop时出现java报错 |
| mapred-env.sh | 运行mapreduce的环境变量,覆盖hadoop-env.sh | Bash | |
| yarn-env.sh | 运行yarn的环境变量,覆盖hadoop-env.sh | Bash | |
| core-site.xml | Hadoop Core配置项,HDFS,YARN,MapReduce的I/O设置 | xml | |
| hdfs-site.xml | hadoop守护进程配置,包括namenode,辅助namenode和datanode | xml | |
| mapred-site.xml | mapreduce守护进程配置 | xml | |
| yarn-site.xml | yarn守护进程配置,包括资源管理器,web应用服务和节点管理器 | xml | |
| slaves | 运行datanode和节点管理器的机器列表 | 纯文本 | |
| hadoop-metrics2.properties | java属性 | ||
| log4j.properties | 系统日志文件 | java属性 | |
| hadoop-policy.xml | 安全模式下运行hadoop时的访问控制列表的配置项 | xml |
core.site.xml配置为全分布模式
1
2
3
4
5
6<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://nn1.hadoop:9000</value> <!--hdfs://namenode/--!>
</property>
</configuration>hadoop-env.sh配置
1
2原本JAVA_HOME的配置为$JAVA_HOME,要改为绝对路径
export JAVA_HOME=/usr/java/jdk1.8.0_201-amd64hdfs-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14<configuration>
<property>
<name>dfs.name.dir</name>
<value>/home/hadoop/name</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>/home/hadoop/data</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
</configuration>mapred-site.xml
1
2
3
4
5
6<configuration>
<property>
<name>mapred.job.tracker</name>
<value>nn1.hadoop:9001</value>
</property>
</configuration>添加masters文件
1
nn1.hadoop
修改slaves文件
1
2s2.hadoop
s3.hadoop将hadoop相关配置完全配置到所有服务器中
1
scp -r /usr/local/hadoop/etc/hadoop/ s2.hadoop:/usr/local/hadoop/etc/hadoop/
启动hadoop集群
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20(1)格式化namenode,第一次启动hadoop服务前执行的操作,以后不需要执行。
hadoop#/usr/local/hadoop/bin/ hadoop namenode -format
(2)启动hadoop集群
hadoop#/usr/local/hadoop/sbin/ start-all.sh
(3)通过jps查看hadoop进程是否正常执行:
Master namenode运行的java进程:
8083 NameNode
8788 SecondaryNameNode
16855 DataNode
7656 ResourceManager
11353 Jps
524 Main
Slave datanode运行的java进程:
3616 DataNode
3751 NodeManager
4203 ResourceManager
19757 JpsZooKeeper环境配置 /usr/local/zookeeper/ 用户属 hadoop:hadoop
修改配置文件/conf/zoo.cfg
1
2
3
4
5
6在配置文件中添加如下配置
dataDir=/data/
server.1=nn1.hadoop:2888:3888
server.2=s2.hadoop:2888:3888
server.3=s3.hadoop:2888:3888将zookeeper所有的安装目录复制到3台服务器中。
新建并编辑myid文件,在上述/dataDir/下建立myid纯文本文件
1
2master为”1“ , slave为”2“, ”3“,对应于上述server编号
echo "1" > /data/myid启动zookeeper集群,注意这个要批量操作,在3台机器上全部启动
1
hadoop#/usr/local/zookeeper/bin/ zkServer.sh start
这里可能出现两个问题:
- SLF4J包冲突 解决办法
- 防火墙问题,参考上述环境设置
如何判断zookeeper集群启动成功
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15批量启动zookeeper的命令(shell脚本):
./ssh_all_group.sh "/usr/local/zookeeper/bin/zkServer.sh start"
zookeeper启动成功标志是在三个服务上都运行QuarumPeerMain
[hadoop@nn1 ssh_learning]$ ./ssh_all_group.sh "jps | grep Quorum"
ssh hadoop@nn1.hadoop jps | grep Quorum
11598 QuorumPeerMain
OK
ssh hadoop@s2.hadoop jps | grep Quorum
20110 QuorumPeerMain
OK
ssh hadoop@s3.hadoop jps | grep Quorum
19952 QuorumPeerMain
OKHBase集群安装与配置 /usr/local/hbase/ 用户属hadoop:hadoop
/conf/hbase-env.sh
1
2
3export JAVA_HOME=/usr/java/jdk1.8.0_201-amd64
export HBASE_CLASSPATH=/usr/local/hadoop/etc/hadoop/
export HBASE_MANAGES_ZK=false/conf/hbase-site.xml
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://nn1.hadoop:9000/hbase</value>
</property>
<property>
<name>hbase.master</name>
<value>nn1.hadoop</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>nn1.hadoop,s2.hadoop,s3.hadoop</value>
</property>
<property>
<name>zookeeper.session.timeout</name>
<value>60000000</value>
</property>
<property>
<name>dfs.support.append</name>
<value>true</value>
</property>
</configuration>同步分发hbase到所有的服务器
启动集群服务
集群启动zookeeper服务
1
./ssh_all_group.sh "/usr/local/zookeeper/bin/zkServer.sh start"
集群启动hadoop服务
1
./ssh_all_group.sh "/usr/local/hadoop/sbin/start-all.sh"
启动hbase服务
1
/usr/local/hbase/bin/start-hbase.sh
集群启动成功的标志:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17Master java服务列表
13969 Jps
8083 NameNode
8788 SecondaryNameNode
13782 HMaster //hbase master进程
16855 DataNode
7656 ResourceManager
524 Main
11598 QuorumPeerMain //zookeeper 进程
Slave java服务列表
3616 DataNode
19952 QuorumPeerMain //zookeeper 进程
22102 HRegionServer //hbase slave进程
3751 NodeManager
22346 Jps
4203 ResourceManager这时出现问题:有的slave服务器并不能启动HRegionServer。原因是因为服务器之间时间不同步。
查看服务器时间命令: date
参考https://blog.csdn.net/liu857279611/article/details/70789504 设置服务器时间同步
1
2
3
4
5
6
7root权限下执行:
1. 安装ntpdate工具
yum -y install ntp ntpdate
2. 设置系统时间与网络时间同步
ntpdate cn.pool.ntp.org
3. 将系统时间写入硬件时间
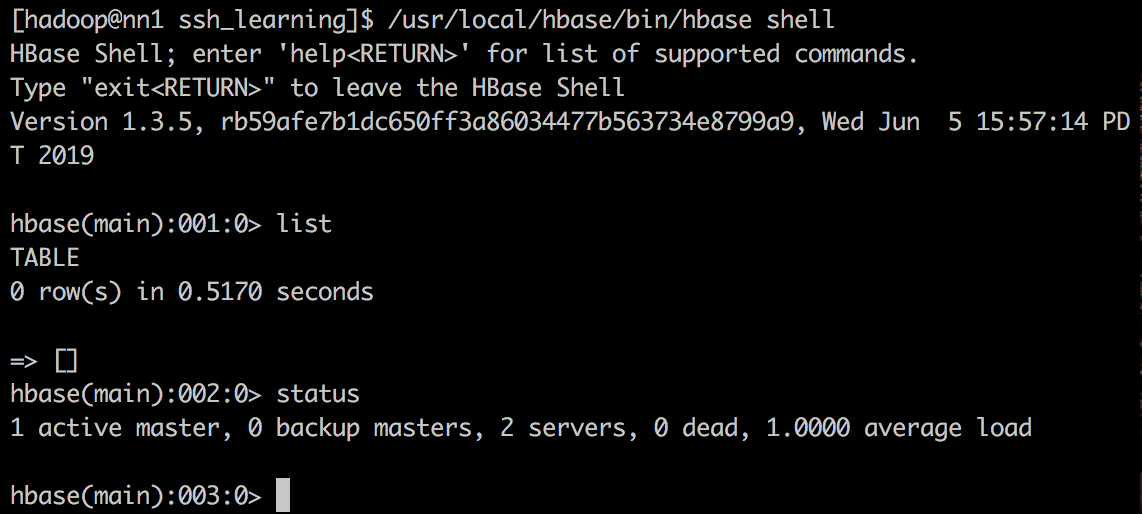
hwclock --systohc启动hbase shell验证
1
/usr/local/hbase/bin/hbase shell