什么是YARN
YARN = Yet Another Resource Negotiator 是Hadoop集群资源管理系统。YARN在Hadoop2被引入,最初是为了改善MapReduce的实现,但具有足够的通用性,同样可以支持其他的分布式计算模式。
YARN提供请求和使用集群资源的API,但这些API很少直接用于用户代码。用户代码中的分布式计算框架提供的更高层API,这些API建立在YARN之上并向用户隐藏了资源管理细节。
1 | YARN的应用 |
YARN应用运行机制
YARN通过两类长期运行的守护进程提供自己的核心服务:
- 管理集群上资源使用的资源管理器(resource manager)
- 运行在集群中所有节点上且能够启动和监控容器的节点管理器(node manager)
容器用于执行特定应用程序的进程,每个容器都有资源限制(内存、CPU等)。一个容器可以是一个Unix进程,也可以是一个Linux cgroup,取决于YARN的配置。
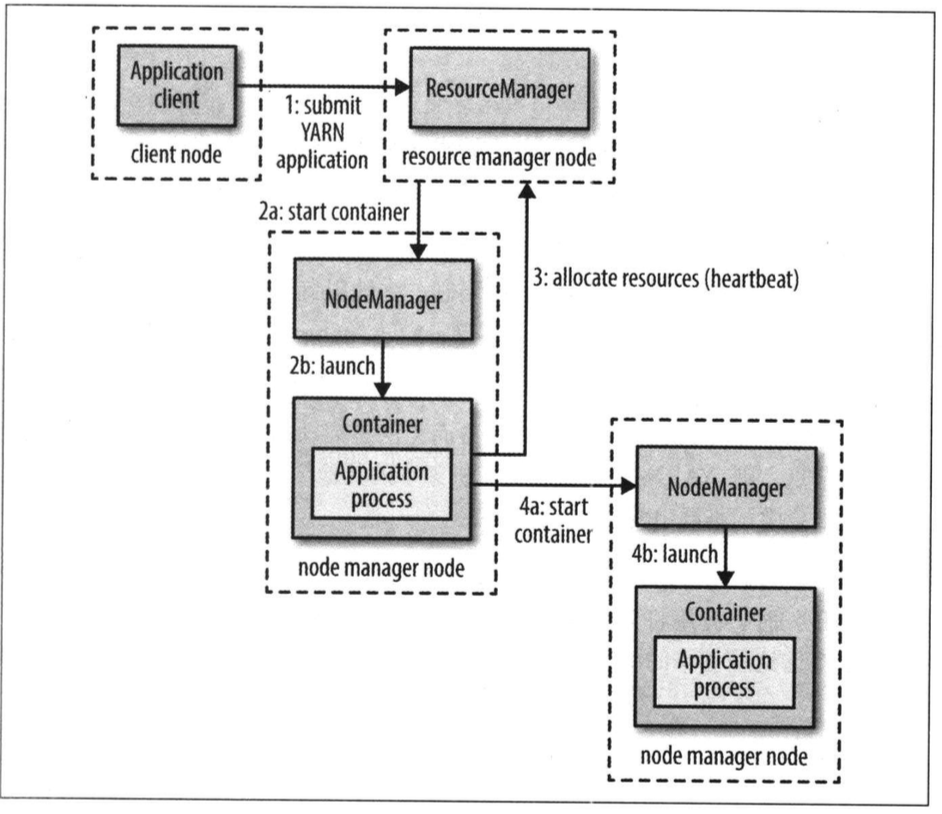
运行机制:
- 客户端联系资源管理器,要求一个application master进程。
- 资源管理器找到一个容器来启动application master的节点管理器。
- application master一旦运行起来之后能做什么依赖于应用本身。YARN本身不会为应用的各部分彼此之间的通信提供任何手段。大多数重要的YARN应用使用某种形式的远程通信机制来向客户端传递状态更新和返回结果,但通信机制都是专属与各应用的。
资源请求:
YARN有一个灵活的资源请求模型。 YARN允许一个应用为所申请的容器指定本地限制。(本地化对于确保分布式数据处理算法高效实用集群带宽非常重要)。
通常,当一个容器用于处理HDFS数据块时,应用将会向这样的节点申请容器:存储该数据块三个复本的节点,或是存储这些复本的机架中的一个节点。
应用生命期:
YARN应用的生命周期差异性很大,按照应用到用户运行的作业之间的映射关系对应用进行分类。
- 一个用户作业对应一个application master。这是MApReduce采用的方式。
- 作业的每个工作流或每个用户对话对应一个应用。比第一个效率高,因为容器可以在作业之间重用,并且可能缓存作业之间的中间数据。Spark采用的方式。
- 多个用户共享一个长期运行的应用。
构建YARN应用
从无到有编写一个YARN应用是一件相当复杂的事情。很多应用都简化了YARN的开发。当一个应用有着复杂的调度需求的时候,YARN项目自身一部分的distributed shell应用为如何写YARN应用做了一个示范。
YARN的好处
可扩展性; 可用性;利用率;多租户
YARN中的调度
调度选项:
- FIFO调度器:不需要任何配置,但是不适合共享集群。大的应用会占用集群中的所有资源。共享集群中更适合使用容量调度或公平调度。
- 容量调度器:预留一定量的资源,一个独立的专门队列保证小作业一提交就可以启动。
- 公平调度器:不需要预留一定量的资源,调度器在所有运行的作业之间动态平衡资源。
YARN的操作
YARN的主要配置
文件路径 /usr/local/hadoop/etc/hadoop/
- yarn-site.xml
- yarn-env.sh
1 | yarn-site.xml |
1 | yarn-env.sh |
启动YARN
首先在各机器上启动zookeeper
1
% /usr/local/zookeeper/zkServer.sh start
在nn1上启动yarn。 start-yarn.sh
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16报错找不到JAVA_HOME,这是因为在hadoop-env.sh中环境变量设置不正确
[hadoop@nn1 hadoop]$ start-yarn.sh
starting yarn daemons
resourcemanager running as process 7168. Stop it first.
localhost: Error: JAVA_HOME is not set and could not be found.
更改:/usr/local/hadoop/etc/hadoop/hadoop-env.sh
export JAVA_HOME=${JAVA_HOME}
改为
export JAVA_HOME=/usr/java/....
[hadoop@nn1 ~]$ start-yarn.sh
starting yarn daemons
resourcemanager running as process 7168. Stop it first.
localhost: starting nodemanager, logging to /usr/local/hadoop-2.9.2/logs/yarn-hadoop-nodemanager-nn1.hadoop.out
查看各节点的进程信息是否有resourceManager和nodeManager
TBC 出现问题